%20--%3e%3ccircle%20cx='32'%20cy='32'%20r='21.5'%20fill='none'%20stroke='%23F4F4F5'%20stroke-width='1.2'%20stroke-dasharray='2.8%204.2'%20stroke-linecap='round'%20opacity='0.42'/%3e%3cline%20x1='39.8'%20y1='27.5'%20x2='46.7'%20y2='23.5'%20stroke='%23F4F4F5'%20stroke-width='4'%20stroke-linecap='round'/%3e%3cline%20x1='39.8'%20y1='36.5'%20x2='47.1'%20y2='40.8'%20stroke='%23F4F4F5'%20stroke-width='4'%20stroke-linecap='round'/%3e%3cline%20x1='27.5'%20y1='39.8'%20x2='23.3'%20y2='47.2'%20stroke='%23F4F4F5'%20stroke-width='4'%20stroke-linecap='round'/%3e%3cline%20x1='24.2'%20y1='27.5'%20x2='16.4'%20y2='23'%20stroke='%23F4F4F5'%20stroke-width='4'%20stroke-linecap='round'/%3e%3ccircle%20cx='32'%20cy='32'%20r='9'%20fill='%23F4F4F5'/%3e%3ccircle%20cx='51'%20cy='21'%20r='5.2'%20fill='%23F4F4F5'/%3e%3ccircle%20cx='51'%20cy='43'%20r='4.6'%20fill='%23F4F4F5'/%3e%3ccircle%20cx='21'%20cy='51'%20r='4.6'%20fill='%23F4F4F5'/%3e%3ccircle%20cx='13'%20cy='21'%20r='4'%20fill='%23F4F4F5'/%3e%3c/svg%3e)
Technology · Blog
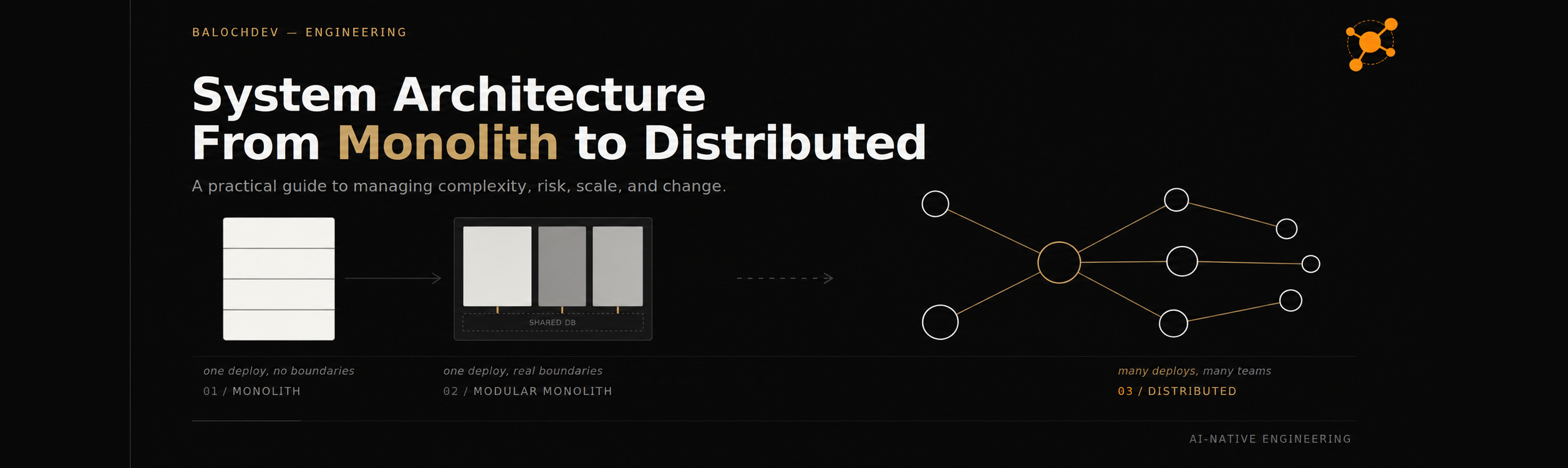
System Architecture Design: A Practical Guide from Monolith to Distributed Systems
A startup ships its first version in six weeks. One codebase, one database, one deploy command. No "platform team," no service mesh, no on-call rotation — just three engineers who know exactly where every line of logic lives.
Then it works. Users show up. A few hundred becomes a few thousand. A Series A gets announced, and the team triples in a year. The codebase that shipped in six weeks now takes forty minutes to build. Deploys that used to be routine now require a Slack thread and someone watching error rates for twenty minutes afterward. A bug in billing takes down search, because somewhere, eighteen months ago, someone imported one file from the wrong place and nobody noticed.
Nothing about the code "went bad." The team didn't get worse at engineering. The architecture that was correct at 1,000 users became wrong at 100,000 — not because it was poorly built, but because the problem it was solving changed underneath it.
This is the part most engineering content skips. Tutorials teach you how to build a monolith, or how to build microservices, as if the choice were a matter of taste or trend. It isn't. Architecture is about managing complexity, risk, scale, and change — in that order, and usually in that order of priority too.
And here's the thing very few engineers say out loud: most architecture decisions are business decisions wearing a technical disguise. "Should we split this into microservices?" is rarely a question about Kubernetes. It's a question about how many teams need to ship independently, how much downtime the business can tolerate, and how much you're willing to spend on infrastructure to buy speed later. Get the business context wrong, and the most "correct" technical architecture is still the wrong decision.
This article is a practical map through that territory — from the simple monolith every successful product probably should start as, through the modular monolith most teams should stay at longer than they think, to the distributed systems some companies genuinely need and many adopt by accident. The goal isn't to make you a fan of any particular pattern. It's to make you confident enough to ask the right question at the right time — and to say "we don't need that yet" when you don't.
A good architecture is not the most sophisticated architecture. It's the simplest architecture that solves today's problems while leaving room for tomorrow's.
The diagram above captures the shape of this whole article: a single block, slowly gaining internal walls, eventually pulling apart into connected pieces — each transition earned, not assumed.
What Is Software Architecture, Actually?
Ask five engineers to define "architecture" and you'll get five different answers, and most of them will be about diagrams. Boxes, arrows, a database cylinder, maybe a load balancer icon. That's architecture's output, not its substance.
Here's a definition that's actually useful day to day:
Architecture is the set of decisions that determine how a system evolves over time.
Not how it runs today. How it changes. A system's architecture is revealed not by what it does on a calm Tuesday, but by what happens when you try to add a feature, replace a vendor, double your traffic, or onboard your fifth engineering team. Good architecture makes those moments routine. Bad architecture makes them archaeological expeditions.
It helps to separate three things people constantly conflate:
Architecture vs. code. You can rewrite a function in Rust instead of Python and the architecture hasn't changed — the system still has the same boundaries, the same dependencies, the same failure modes. Architecture lives one level above syntax: "what talks to what, and who owns what," not "how is this loop written."
Architecture vs. design patterns. A design pattern — Factory, Observer, Strategy — solves a local problem inside a piece of code. Architecture solves a systemic problem across services, teams, and time. You can write beautiful, pattern-rich code inside a module that's still part of a terrible overall architecture, the same way a well-organized desk doesn't fix a poorly organized building.
Architecture vs. infrastructure. Infrastructure is what your system runs on — EC2, Kubernetes, an RDS instance. Architecture is what your system is — the boundaries between its parts. You can run a monolith on Kubernetes (plenty do, often unnecessarily) and run microservices on three rented VPS boxes. Infrastructure should follow architecture, not lead it. A lot of overengineering starts the day a team picks the infrastructure first and designs an architecture to justify it.
Why does this matter? Architecture is expensive to undo. You can refactor a function in an afternoon. Untangling a wrongly-drawn service boundary, or migrating a database three other systems quietly depend on, is a multi-quarter project with real business risk attached. The cost of a bad decision doesn't show up for a year — by which point it just looks like "how things are."
Takeaway: Before debating what architecture to use, get clear on what architecture even means in your context — code organization, infrastructure topology, or the actual boundaries of change. Conflating these three is where a lot of unproductive arguments start.
The Monolith: Where Most Systems Should Start
A monolith is a single deployable application. One codebase, one build, one process boundary (even if it runs on many machines), one database in the common case. Everything — your API, your business logic, your background jobs — ships together and deploys together.
In certain corners of the industry, "monolith" has become a slightly embarrassing word, like admitting you still use a flip phone. That reputation is almost entirely undeserved.
Consider what a monolith actually buys you:
Simplicity of mental model. When something breaks, there's one codebase to grep, one log stream to tail, one stack trace with the entire call path. You don't need distributed tracing to answer "why did this request fail" — a debugger and twenty minutes usually does it.
Faster development, especially early on. A feature touching "orders," "inventory," and "notifications" is a single pull request, tested and deployed together. No coordinating release schedules across teams.
Lower operational complexity. One thing to deploy, one to monitor, one database to back up. No message broker to keep alive, no service discovery to configure.
Transactional integrity for free. If placing an order needs to update three tables atomically, a monolith gives you a database transaction. The distributed equivalent — sagas, compensating actions — is real engineering work a monolith simply doesn't need.
This isn't a nostalgia argument. It's a track record. Amazon ran as a single large application for years before its well-known service-oriented rewrite, and built an enormous business doing so. Shopify, processing a meaningful share of global ecommerce today, runs on a Ruby on Rails monolith and has been vocal about defending that choice rather than abandoning it. GitHub built one of the most heavily-used developer platforms on Earth largely on a Rails monolith. These weren't companies that "hadn't gotten around to" microservices — they understood the monolith was the right tool for their stage, and in Shopify's case, for a long time after.
The most common misconception: that a monolith means a badly organized application. It doesn't. "Monolith" describes deployment topology, not code quality. You can have a beautifully modular, cleanly separated monolith (more on this shortly), and you can have a tangled, incomprehensible set of microservices. The deployment boundary and the code quality are independent variables. Conflating them is how teams talk themselves into a premature rewrite, thinking "we need microservices" when what they actually need is "we need to stop writing spaghetti."
A monolith isn't a starter architecture you're supposed to outgrow. It's a legitimate architecture you eventually might outgrow — and a lot of companies never do.
Practical takeaway: If you're building something new and you're not yet sure what the product even is, a monolith isn't a compromise — it's the correct engineering decision. The cost of being wrong about your domain model is much lower when everything lives in one place and can be reshaped quickly.
When Monoliths Start Hurting
None of this means monoliths are free forever. They have a shape of pain that shows up reliably, and it's worth knowing the symptoms so you can recognize them instead of mysteriously feeling like "things have just gotten harder."
Team growth outpaces module boundaries. At five engineers, everyone roughly knows the codebase. At fifty, nobody does — and if the code itself enforces no boundaries, fifty engineers are all editing the same files, stepping on each other. The org chart grows faster than the code's internal structure, and that mismatch is where most monolith pain actually originates.
Deployment risk increases with surface area. A one-line footer change rides along with a payments fix in the same release, same risk profile. As the codebase grows, the blast radius of any deploy grows with it. Teams start fearing deploys — and fear of shipping is fear of feedback.
Scaling bottlenecks concentrate in the wrong places. If your image-processing endpoint is CPU-heavy and your user-facing API needs to stay fast and cheap, a monolith forces you to scale the whole application — more replicas of everything, even the parts that didn't need it.
Tight coupling becomes load-bearing. Nobody plans to couple User to Billing, Notifications, and Analytics. It happens one convenient import at a time, until "update the user's email" touches six unrelated systems because they all reached directly into the same table instead of going through a defined interface.
Build and test times become a tax on every change. A test suite that took ninety seconds at launch can take forty minutes three years later. When the feedback loop stretches from a minute to an hour, engineers batch changes, review less carefully, skip local testing. The architecture is now shaping — and degrading — engineering culture.
None of these symptoms says "you need microservices." They say "your monolith has outgrown its current internal structure" — and the fix for most of this isn't distribution, it's better boundaries within the system you already have.
Practical takeaway: When a monolith starts hurting, the instinct is to reach for microservices. Resist that instinct until you've ruled out the cheaper fix: better modularity inside the monolith you already have.
Architecture Smells: How to Tell Before It's a Crisis
The symptoms above are specific to monoliths. But there's a shorter, more general checklist that works regardless of what you've built — the architectural equivalent of a code smell. None of these are failures on their own. Two or three of them together, persisting for months, mean your architecture is past its expiration date for your current team.
Nobody can say, without checking, who owns a given module or service.
Deployments require a meeting, a calendar hold, or a specific person to be online.
A "small" feature routinely touches code in three or four unrelated areas.
One component failing takes down parts of the system that have nothing to do with it.
Engineers visibly hesitate before deploying — or batch changes to deploy less often.
A database schema change makes more than one person nervous.
New engineers take noticeably longer than they should to ship their first real change, because nobody can explain the whole system to them in an afternoon.
None of these point to a specific fix. That's the point — they're a diagnosis, not a prescription. A team that recognizes three or more of these usually has a boundary problem, not a technology problem, and the right next step is almost always the modular monolith work in the next section, not a rewrite.
Modular Monoliths: The Most Underrated Architecture in the Industry
If there's one section of this article worth bookmarking, it's this one.
A modular monolith is still a single deployable unit — one build, one deploy, often one database — but the internal code is organized into clearly bounded modules with explicit interfaces between them. Orders doesn't reach directly into Inventory's database tables; it calls a defined interface. Billing doesn't import User's internal helpers; it depends on a public contract User exposes deliberately.
Think of it as a building with real internal walls and clearly marked doors, instead of one open-plan room where anyone can walk anywhere.
Concretely: each domain lives in its own folder with a defined public interface; cross-module communication happens only through those interfaces, never by reaching into another module's internals; each module could be extracted into its own service later, because the boundary already exists in code; you still get one deploy, one transaction model, one operational surface.
This is, frankly, where a large share of companies should simply stop. Not because microservices are bad, but because the modular monolith already solves the actual pain points — tight coupling, unclear ownership — without network calls, distributed failure modes, or a tenfold increase in operational surface area.
A useful test: if your "microservices" all share one database and deploy on the same schedule, you don't have microservices — you have a monolith with extra network latency and none of the benefits.
A practical example. A SaaS billing platform structured like this inside one codebase:
/src
/billing (public interface: BillingService)
/subscriptions (public interface: SubscriptionService)
/users (public interface: UserService)
/notifications (public interface: NotificationService)
/shared (types, utilities — no business logic)SubscriptionService needs to know if a payment method is valid. It doesn't query billing's tables directly — it calls BillingService.hasValidPaymentMethod(userId). That one decision — go through the interface, never around it — is the entire discipline that makes this work, and it pays off enormously the day billing needs to become its own service, because the seam is already cut.
The boundary that matters most isn't between servers. It's between modules. Get that right first, and where things physically run becomes much easier to answer later.
Practical takeaway: Before reaching for microservices, ask whether you've actually built clean module boundaries inside your current monolith. If you haven't, microservices won't fix your coupling problem — they'll just make it harder to see, because now it's hiding behind a network call instead of an import statement.
Distributed Systems: Why Companies Actually Move Beyond a Monolith
When a team genuinely outgrows even a well-organized modular monolith, it's usually for one or more of four reasons — and notice that none of them are "because microservices are more modern":
Independent scaling. A video transcoding pipeline and a customer-facing dashboard API have nothing in common in CPU, memory, or traffic patterns. Separate services let you scale each according to its actual needs.
Team autonomy. The big one, and it's organizational, not technical. Once you have eight backend teams deploying from the same repo on the same release train, coordination tax grows faster than the value it produces. Separate services let separate teams ship on separate schedules without a release manager playing air traffic controller.
Reliability requirements that differ by component. Payment processing might need 99.99% uptime with careful idempotency. An internal admin dashboard can be down for twenty minutes and nobody notices. Bundling both means the less-critical component drags down how fast you can move on the more-critical one.
Geographic and regulatory distribution. Some systems need to run close to users in different regions, or keep data within specific jurisdictions for compliance. No amount of clever monolith design solves that from a single deployment.
Every legitimate reason to distribute is about people, risk, or physics — not "microservices are the modern way to build software." If your reason doesn't map to one of these four, ask honestly whether you're solving a real problem or chasing an aesthetic.
Practical takeaway: Distribution is a means, not a goal. If you can't name which of these four pressures is driving the decision, you're probably not ready to distribute yet — or you're distributing for the wrong reason.
Microservices: Real Benefits, and the Costs Nobody Puts on the Slide
Microservices, done for the right reasons, deliver real value:
Independent deployment. Teams ship on their own schedule without waiting for a company-wide release train.
Clear ownership. A service has a team that owns it end to end — its uptime, its on-call, its roadmap.
Targeted scalability. You scale the parts that need scaling, and only those parts.
But the costs are real too, and they tend to be invisible right up until the moment they aren't.
Operational complexity multiplies, it doesn't add. Ten services isn't ten times the complexity of one — it's closer to ten times the number of ways they can interact and fail. You now need service discovery, centralized logging, distributed tracing, and a deployment pipeline per service, because no single dashboard tells the whole story anymore.
Distributed debugging is a harder skill. In a monolith, a stack trace tells you the whole story. In a distributed system, a failed request touched four services, and the root cause might be a fifth that returned slow-but-successful responses, causing a timeout three hops downstream. Without tracing from day one, debugging becomes detective work.
Network failures are now constantly your problem. Every service-to-service call can fail in ways a function call never can: timeouts, partial failures, retries that turn a blip into a thundering herd. The fallacies of distributed computing aren't theoretical — every team relearns them the hard way, usually mid-incident.
Observability stops being optional. Without tracing, metrics, and correlation IDs threading through every request, you genuinely cannot answer "why is this slow" — not because you're bad at your job, but because the information is now scattered across a dozen processes that don't naturally talk to each other.
Data consistency becomes a design problem, not a database feature. "Update the order and decrement inventory" is one transaction in a monolith. Across two services, it's no longer atomic — you're choosing between eventual consistency or distributed transaction patterns (sagas, compensating actions) that are genuinely harder to write and reason about than BEGIN; ... COMMIT;.
Here's the unpopular part: microservices are not "more advanced" than a monolith. They're a different tradeoff, optimized for a different problem. A team that adopts them without the organizational pressure that justifies them isn't being sophisticated — they're trading a known cost (a big codebase) for a less familiar one (distributed failure modes), often without realizing the trade was made.
A failure mode worth naming directly: a ten-person startup splits into fifteen microservices because that's "how scalable companies do it." Now ten engineers maintain fifteen deployment pipelines, and a request that used to be one function call is three network hops with three new ways to fail — for a system that didn't need any of this. It happens because microservices are easy to start and hard to feel the cost of until eighteen months in.
Microservices don't remove complexity. They redistribute it — out of your codebase and into your network, your infrastructure, and your team's cognitive load.
Practical takeaway: Before splitting a service, write down — concretely — which of the four legitimate reasons for distribution (from the previous section) you're solving for. If you can't, you're paying network-call costs to solve a problem that better module boundaries would have solved for free.
Event-Driven Architecture: Power and a Different Kind of Mess
Event-driven architecture flips the usual request/response model. Instead of Service A calling Service B and waiting, Service A publishes an event — "OrderPlaced," "PaymentFailed" — to a message broker (Kafka, RabbitMQ, SQS), and any number of consumers can subscribe and react, without the producer knowing who's listening.
Take an ecommerce checkout. Placing an order might need to charge payment, decrement inventory, send a confirmation email, notify the warehouse, update analytics, and calculate loyalty points. Calling all six synchronously couples checkout's reliability to all six — if analytics hiccups, should the order actually fail? No. With events, checkout does one thing: place the order, emit OrderPlaced. Each downstream concern subscribes independently, retries on its own failures, and can be added later without touching checkout at all.
This is where event-driven systems shine: decoupling producers from consumers, and decoupling the user-facing transaction from everything that doesn't need to happen synchronously.
+-------------------+
Checkout ----> | OrderPlaced | (event bus / broker)
(writes once) +-------------------+
| | |
v v v
Payment Inventory Email
(charges) (decrements) (sends)
|
v
Analytics, Loyalty, Fraud...
(subscribe whenever, no checkout changes needed)Checkout only ever talks to the event bus. Every box underneath it can fail, retry, or get added later without anyone touching the checkout code.
Where they get difficult — consistently underestimated:
Tracing a request becomes genuinely hard. "Why didn't the confirmation email send?" is no longer a stack trace; it's an investigation across a broker, consumer logs, and possibly a dead-letter queue.
Ordering and duplication become real design problems. Most brokers offer at-least-once delivery, not exactly-once — your consumers need to be idempotent, or you'll double-charge a card during a network blip.
Eventual consistency becomes visible to the business, not just engineers. If inventory decrements a few hundred milliseconds after checkout, two customers could both see "in stock" for the last unit. That's the architecture working as designed — but support teams need to understand it, not discover it during an incident.
Schema evolution is a coordination problem across every consumer. Change the shape of an OrderPlaced event, and every subscriber — possibly owned by teams you don't talk to daily — needs to handle it gracefully, or you've caused a silent, distributed outage.
Event-driven architecture fits genuinely asynchronous concerns — notifications, analytics, audit logging — where "eventually" is an acceptable answer to "when." It's a poor fit for anything the user is waiting on synchronously, like "did my payment go through."
Practical takeaway: Use events for what can happen later. Use direct calls (or a single transaction) for what the user is waiting on right now. Mixing those up in either direction is where most event-driven systems go wrong.
Databases and Architecture: The Decision Nobody Revisits Soon Enough
Architecture conversations love to focus on services and rarely spend enough time on data — which is strange, because data is usually the hardest thing to change after the fact. You can rewrite a service in a weekend. Migrating a production database with zero downtime, while three other systems quietly depend on its current shape, is a project that can take months.
Shared database, multiple services. Several services read and write the same database — risky, but also how a lot of "microservices" that are really modular monoliths in disguise actually operate, often successfully early on. The risk: the schema becomes an unintentional shared contract, and a change in service A silently breaks service B's queries.
Database-per-service. Each service owns its database completely; nothing else queries it directly. This is the "real" microservices pattern — it delivers independent deployment, since a service's schema can change freely. The cost: data spanning two services now needs an API call or a duplicated, eventually-consistent copy. No more "just JOIN across tables."
+------------+ +------------+ +------------+
| Orders | | Billing | | Users |
| Service | | Service | | Service |
+------------+ +------------+ +------------+
| | |
v v v
+------------+ +------------+ +------------+
| orders_db | | billing_db | | users_db |
+------------+ +------------+ +------------+
Orders needs the user's email? It calls Users' API.
It never queries users_db directly.SQL vs. NoSQL is a data-shape decision, not really an architecture decision. Relational databases earn their keep with real relationships and transactional guarantees — financial records, inventory. Document or key-value stores earn theirs with self-contained data and flexible schema — sessions, activity feeds, catalogs with varying attributes. The mistake is picking one as an identity ("we're a NoSQL shop") instead of per use case.
Read replicas scale read-heavy workloads — dashboards, reports, search — by routing reads to a replica while writes go to the primary. One of the highest-leverage, lowest-risk scaling moves available, since it needs no redesign, just infrastructure.
Caching (Redis, an in-process cache) sits in front of expensive reads and is consistently underused relative to the performance it buys. The discipline it requires is invalidation — deciding when cached data goes stale. Get that wrong and you've traded a slow-but-correct system for a fast-but-occasionally-wrong one, often a worse trade.
Most teams redesign their services long before they're forced to redesign their data layer — and then discover the data layer was the actual bottleneck all along.
Practical takeaway: Before splitting services, ask what happens to your data. If the honest answer is "we'd need two services constantly querying each other's database to make this work," you haven't found a service boundary — you've found a single domain you're about to awkwardly cut in half.
Architecture Principles That Actually Scale
Patterns come and go in popularity. These principles don't, because they're not about technology — they're about how complexity behaves over time.
Separation of concerns. Each part should have one clear reason to change. Billing changes when pricing logic changes — not when the notification template changes. Editing the same file for two unrelated reasons is the signal a boundary is in the wrong place.
Loose coupling. Components depend on interfaces, not internals. The test: can you change a module's implementation without touching anything that calls it? If changing how UserService stores a password requires updates in four unrelated files, you don't have it.
High cohesion. Things that change together should live together. A User module containing profile, authentication, and preferences is more cohesive than user logic scattered across six folders added in six different sprints.
Fault isolation. A failure in one part shouldn't take down an unrelated part — the entire argument for circuit breakers and timeouts in distributed systems, and just as relevant in a monolith, where a runaway background job shouldn't starve the web server.
Observability. You cannot operate what you cannot see. Logs, metrics, and traces are the nervous system that tells you whether the above principles are holding up in production, not just on a whiteboard.
Simplicity. The most underrated principle here. Every layer of abstraction has to earn its complexity by removing more pain than it introduces. The architectures that age well aren't the cleverest — they're the ones a new engineer understands by their second week.
Practical takeaway: When evaluating any architecture decision, run it through these six principles like a checklist. Most bad decisions violate at least two of them simultaneously, and that combination is usually visible in advance if you stop to check.
Common Architecture Mistakes (and Why They Keep Happening)
Premature microservices. Splitting before any of the four legitimate distribution reasons actually apply. The team pays the full operational cost — network calls, deployment pipelines, observability tooling — for a system a modular monolith would have served perfectly well.
Building for imaginary scale. Designing for ten million users when you have two thousand, "just in case." This is a tax paid today against a future that may never arrive, and it often makes the system harder to change once real requirements show up, because you're unwinding speculative complexity instead of adding to a simple base.
Ignoring observability until it's an emergency. Teams treat logging as something to "add later," until a 3 a.m. incident where nobody can answer "what's happening right now." It's dramatically cheaper to build before you need it than during an outage.
Tight coupling disguised as convenience. "I'll just import this one helper, it's faster than a proper interface." Each instance is genuinely faster. A hundred such shortcuts over two years is how a modular monolith quietly becomes an untangleable blob.
Overengineering for flexibility nobody asked for. Abstract factories for one implementation, plugin architectures for features with only one variant. Flexibility has a cost — more code, more indirection — and should be purchased against a real, observed need.
Copying Netflix's architecture without Netflix's problems. Netflix runs hundreds of millions of users with an engineering org of thousands. Their architecture is a correct answer to their problem, and very likely the wrong answer to one with two thousand users and six engineers. Borrowing the solution without the problem is cargo-culting, not engineering.
The architecture mistake that costs the most isn't picking the wrong pattern. It's picking a pattern sized for a problem you don't actually have.
Practical takeaway: Most architecture mistakes share one root cause: solving for a future or a scale that hasn't arrived yet, at the expense of the present, which has. When in doubt, build for the problem in front of you, and leave clean seams for the problem that might come later — don't build the later problem's solution prematurely.
A Practical Decision Framework
Theory is easier to apply with a concrete framework: a sequence of questions, in order — each one matters only if the previous answer opens the door to it.
Should I stay monolithic?
Is the team smaller than roughly 15–20 engineers on this product?
Is the domain model still actively changing as you learn what the product is?
Can a single team realistically understand the whole system?
Is current traffic served well by scaling one application horizontally?
Mostly yes: stay monolithic. For a large share of products, this is the permanently correct answer, not a phase you're passing through.
Should I modularize?
Are unrelated parts of the codebase stepping on each other?
Is it getting hard to say who owns what?
Do you suspect tight coupling between domains that shouldn't be coupled?
Has the team outgrown holding the whole system in their heads?
Mostly yes: invest in module boundaries now, before anything more drastic. Often the single highest-leverage move available, and cheaper than it sounds — you're reorganizing code you already have.
Should I move to microservices?
Do separate teams need to deploy on separate schedules, without waiting on each other?
Do specific components have radically different scaling profiles forcing you to over-provision everything?
Do specific components have meaningfully different reliability requirements constraining how fast you change less-critical parts?
Is there a real, current need for geographic or regulatory distribution?
A concrete current example for at least one: extracting that specific service is reasonable. "This is how good teams do it" is not a yes — go back to the modular monolith.
Should I introduce event-driven architecture?
Are there steps that genuinely don't need to happen synchronously with the request?
Would decoupling producer from consumer let you add functionality without touching existing code?
Can the business tolerate eventual consistency for this workflow?
Do you have, or will you build, the observability to trace an event through multiple consumers?
Yes to the first three, honest about the fourth: event-driven patterns will likely pay off. No observability yet? Build that first.
Practical takeaway: Work through these four questions in order, every time. Skipping ahead — jumping straight to "should we use microservices" without first asking "should we modularize" — is the single most common path to architecture regret.
The BalochDev Perspective
We work primarily with startups and growing product teams, and one pattern shows up over and over: teams adopt complexity before they adopt discipline.
A founder hears "microservices" at a conference, or reads a blog post from a company three hundred times their size, and the architecture conversation becomes about which pattern to adopt rather than which problem to solve. We've sat in planning sessions for systems with a few thousand users where the proposed design had more moving parts than the product had features.
The honest version of our advice is almost always less exciting than what gets shared on social media: most systems don't need microservices. Most systems need clearer module boundaries, real observability, and a deployment process that doesn't require a meeting. We've seen teams spend months building infrastructure sized for millions of users while still struggling to reliably serve thousands — and the fix was never more infrastructure. It was going back and drawing the boundaries they'd skipped the first time.
The architecture question we actually want teams to ask isn't "what would a top-tier engineering team build?" It's "what does our team, at our stage, with our constraints, need in order to keep shipping without breaking things?" Almost every good architecture decision we've been part of started with that second question, not the first.
Case Study: The Evolution of a SaaS Product
To make this concrete, here's a realistic (composite, fictional) journey — the kind of progression that shows up, with minor variations, across a huge number of real SaaS companies.
Stage 1 — Simple monolith. Three founding engineers build a project management tool. Next.js frontend, one Node.js backend, one Postgres database. Everything ships in one deploy — there's one obvious way to build this, and it's the right way. Eight months in, they have paying customers.
Stage 2 — Growing pains. Eighteen months later: real revenue, twelve engineers, first cracks. Build times have crept from ninety seconds to twelve minutes. Engineers keep colliding in the same files because "notifications" code is scattered across four folders, depending on which feature it was originally written for. Nobody planned this — it accumulated.
Stage 3 — Modular monolith. Rather than reach for microservices, the team spends six weeks establishing clear module boundaries — projects, billing, notifications, users, integrations — each with an explicit public interface, each forbidden from reaching into another's internals. Same deploy, same database. Just real walls where there used to be an open floor plan. Velocity improves almost immediately.
Stage 4 — Selective extraction. Two years in, with forty engineers, two specific pressures emerge. The integrations module syncs with flaky third-party APIs, and its instability occasionally degrades the entire application because everything shares one process. The notifications module has become a genuinely high-volume async workload with a completely different scaling profile. The team extracts exactly these two — not a "microservices migration," but two specific, justified decisions. Everything else stays put.
Stage 5 — Distributed, deliberately scoped. By year four, with eighty engineers and customers across continents, a real distributed architecture has emerged — one justified extraction at a time, never a single "rewrite everything" initiative. The core domain is still a large, modular monolith. Around it sit half a dozen extracted services, each pulled out for a documented reason, communicating through defined APIs and an event bus for genuinely asynchronous work.
Notice what didn't happen: nobody woke up one day and rewrote everything as microservices. The architecture grew one justified decision at a time — which is exactly how it should.
Final Thoughts
Architecture is a journey, not a destination — not in the inspirational-poster sense, but literally. The right architecture today isn't a fixed target. It's a moving answer to a moving question: given our current team, traffic, risk tolerance, and understanding of the domain, what's the simplest structure that won't actively work against us?
The best architecture is rarely the most impressive one. It's the one that lets a team move quickly without breaking things constantly, operate reliably without a war room on standby, and adapt to change without a quarter-long migration every time the business pivots.
If you take one thing from everything above: architecture decisions are business decisions wearing technical clothes. Every time you're tempted to choose a pattern because it's modern, ask what business pressure it's actually solving — team autonomy, independent scaling, reliability isolation, regulatory need. Name the pressure, and the right architecture usually becomes obvious. Can't name it? You're probably not ready to decide yet — and that's a fine reason to wait.
Start simple. Add structure when structure earns its cost. Distribute when distribution solves a problem you actually have, not one you're worried about having someday.
Frameworks will change. The database you're using today will be replaced by something better in a few years, and so will the one after that. Engineers will keep arguing about monoliths versus microservices long after both words sound dated. What won't change is the underlying job: managing complexity without slowing down the people building the system. The teams that win aren't the ones with the most sophisticated architecture. They're the ones that know, at every stage, exactly how much architecture they actually need — no more, and no less.
Pull quotes for reuse:
"Architecture decisions are business decisions wearing a technical disguise."
"A good architecture is not the most sophisticated architecture. It's the simplest one that solves today's problems while leaving room for tomorrow's."
"A monolith isn't a starter architecture you're supposed to outgrow. It's a legitimate architecture you eventually might outgrow — and a lot of companies never do."
"Microservices don't remove complexity. They redistribute it — out of your codebase and into your network, your infrastructure, and your team's cognitive load."
"Most teams redesign their services long before they're forced to redesign their data layer — and then discover the data layer was the actual bottleneck all along."
"The architecture mistake that costs the most isn't picking the wrong pattern. It's picking a pattern sized for a problem you don't actually have."
"Teams adopt complexity before they adopt discipline."
"The teams that win aren't the ones with the most sophisticated architecture. They're the ones that know, at every stage, exactly how much architecture they actually need."
Want to advertise here? See our ad placements · [email protected]
Related articles

Why We're Building — and Why We're Writing About It
BalochDev is a software studio building websites, web apps, AI features, and language technology from Balochistan. This is our first post — not a welcome message, but a position: why we started, what…

The AI Model Race Won’t Build Your Product: What Actually Matters for LLM Integration in 2026
GPT-5. Apple Intelligence. Anthropic Mythos. A new frontier model launches every few weeks. Here’s what that race means if you’re the one actually shipping.
0 Comments
No comments yet — be the first.